In section 1.5.2, you already read about the major pros and cons of genetic programming as a strategy for breeding problem solutions. In the last sections, we talked about some impacts of genetic programming as a basis of OOOPS. But we have not yet seen how genetic programming really works. Moreover, you will probably ask why we breed the OOOP programs and not try to design them manually. Why not use the techniques that are common in multiagent systems research? Until now, manual computer programming has produced much more powerful and complex programs than automatic evolution. Is it really a good approach to let the OOOP programs emerge on the basis of chance?
Well, for being able to judge about GP, we first have to know how it tries to reach its goal of constructing good programs for a given problem. So we will first have a look at the GP approach and then talk about its use for developing OOOP programs.
In this section, we will run through a little "GP in a nutshell" introduction to genetic programming1. As we have seen in section 1.3, natural evolution uses two main principles for developing good solutions: variation and selection. The genotype is varied and if this variation results in advantages for the phenotype, the latter has a bigger probability of being selected for reproduction and not dying early. In natural evolution, the individual is not selected by "somebody" for inducing a specific direction of development. The selection is an implicit result of the competitive and dangerous nature of the environment. The direction of development emerges on this basis and explores the best strategies for coping with the problems given by the environment.
This feature of natural evolution is used when breeding creatures or plants to meet certain human conceptions or preferences. The environment is created or influenced by the breeder so to enforce a specific direction of development. Only individuals with "good" attributes are being given the possibility to reproduce. Evolutionary computation uses the same principles. The environment is given by the human designer and includes a fitness function which determines how good the individual solves a given problem. The resulting fitness value sets the probability for the individual to reproduce or die. In the case of GP: if the individual (i.e. the program) meets well the features defined as "good" in the fitness function (which mainly but not necessarily only2 means that it produces "good" results when executed), it gets a high fitness value. This in turn causes the evolutionary algorithm to give this program a high probability of survival and reproduction. What does that mean?
"High" is a relative word. If there is nothing to compare with, you cannot denote something as high. The fit individual has a high probability of survival and reproduction because there are other individuals that have a lower probability. Selection needs a set of possibilities to choose from. So in a GP run, not a single individual but a population of individuals is evolving. Also in nature, evolution can only work with a population of individuals. For evolution to continue, this population has to ensure that there remain different possibilities for selection to choose from. If all the individuals in a population have the same genome, there cannot be any progress any more.
This said, we can understand what it means for a GP individual to have a high probability of survival and reproduction. It means that it is very probable that the program remains in the population and it has a high probability to multiply by being chosen to replace other less fit individuals. As natural offspring always has a slightly different genome compared to its parents and thus ensures variation in the population, these "copies" of the fit program that replace other died individuals are also being varied. But to speed up the evolutionary search, also most parent individuals are being varied after the selection step. Only some of the best individuals (the elite) might survive without being changed. This ensures that the best solution is not lost again.
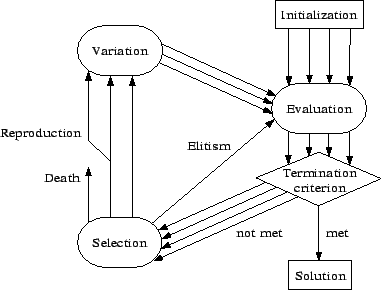
In a nutshell, the execution of an evolutionary algorithm like genetic programming can be described as the evaluation-selection-variation loop shown in figure 3.13. A pass through this loop is called one generation, because new offspring has come into being.
First, an initial (often random) population is created. All the programs in this population are then executed and their fitness evaluated. If a termination criterion4 is met, the best program is presented as the problem solution. If the breeding has not yet reached its goal, selection decides on the basis of the computed fitness values what to do with the different individuals. There are many different possible selection methods, but all base on chance and on the fitness of the individual5. A fitter individual has a greater probability to survive and produce offspring, but that does not mean that an unfit individual cannot get these privileges. It just has a smaller probability to do so.
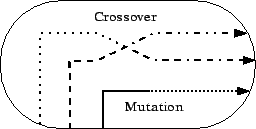
Most individuals are then varied. There are two main types of variation which are shown in figure 3.2. We met these two mechanisms that can change the genotype already in section 1.3. Mutation makes random changes to the genome (which in GP is the program code) of one individual and crossover mixes parts of the genomes of two individuals. Depending on the type of programming language and on the used function set6, the variation operators have to work very differently for producing valid programs. A simple example of a mutation in GP would be to change one command in the program code.
The varied programs are then run and evaluated again to begin a new generational loop.
Now, you might say: "OK, this is a nice simulation of natural evolution. But why should we use this for designing problem solving systems? Are the traditional techniques for program development not good enough?" Yes and no. For many problems the traditional program design processes are the best or even the only feasible way of creating good solutions. It is impossible to evolve a word processor like Starwriter7 with genetic programming techniques. Firstly, it would be impossible to define a suited fitness function except perhaps user satisfaction. Secondly, the evolution (or more exactly: breeding) would take ages. And thirdly, EC which relies on interactive evolution--which uses an evaluation of individuals based on humans rating their quality--produces many problems like, for example, the huge amount of time and human resources needed for evaluation. But interactive programs can only be evolved by interactive evolution or with a simulated user. And simulating a user of a word processor is much harder than writing the word processor itself.
But this is not our goal. We do not want to breed an office suite. We know quite well how to program such systems with the traditional techniques. But there are problems that cannot be solved with these techniques. We already talked about this in section 2.1.3 where I pointed out the advantages of OOOP compared to traditional programming techniques. So let us say we want to use object-oriented ontogenetic programming because of its many advantages but we do not want to breed the OOOP programs but write them by hand. OK, but how do you think the genome should be programmed so that the intended cooperation between the cells emerges? That is the problem: The interactions of genes and cells in OOOP are so complex, that we do not have any idea how to change the genotype (the program code) for getting a desired effect in the phenotype (the running program). Current molecular biology research at present has reached a similar problem: We now know the "program code" of the human species (the genome), but that does not help us a lot because we have no idea what to change for getting a desired effect. Most attributes of human beings (like heritable diseases, which are the most accepted candidates for gene therapy) are based on the interaction of many genes. And even if you change all of them, you never know which side effects this will have on other interactions and resulting attributes. Fortunately, we do not breed humans. But the experiences in breeding other creatures and plants show, that breeding works quite well and is very easy compared to direct gene manipulation.
In nature, molecular approaches to changing attributes of creatures are very interesting because breeding takes ages whereas manual gene modifications produce results already in the next generation. As we know, also genetic programming takes quite a lot of time and manually changing the program code is a much faster method for improvements if one knows what to change. But we do not know what to change until now, and it will probably take very long until we find good methods for manual design and optimization of systems using gene regulation processes. Since artificial evolutionary approaches like genetic programming are quite easy to apply and seem to work much faster than breeding natural creatures, this is the current method of choice for developing systems based on object-oriented ontogenetic programming.
As we will see in section 4.2, OOOP can be extended to be an ideal method for programming swarms of cooperating units. And at the moment, genetic programming is the ideal method for developing such OOOP programs, because there is no other feasible way. Trying different strategies by hand like it has been done in many works on swarm interactions [Stephens and Merx, 1990,Korf, 1992,Mataric, 1995,Hemelrijk, 1997,Bonabeau et al., 1999] is very improbable to lead to good solutions for difficult problems. Moreover, searching a good solution manually takes much human time whereas a genetic programming run only takes much computer time. The human user can do other things while waiting for the computer to find the solution. Unlike human work, computing resources get cheaper and faster all the time. And trying different changes in programs is not a work for which it would be easy to find employees, even if they are well paid. This is also one of the main problems of interactive evolution. If it cannot be organized so that the evaluation by the user is a by-product of other work or leisure, it has not a big chance for success because it will be difficult or extremely expensive to find enough users for doing the evaluations. OOOPS does not have these problems. It can work on a problem without any user interaction because it includes a simulation of the problem environment, and with using genetic programming it finds good solutions on itself. David Evans writes in [Evans, 2000]:
We are a long way ...from solving the deeper problem of how to program swarms of computing devices.The combination of object-oriented ontogenetic programming and genetic programming used in OOOPS and even more its extension to "Swarm-Programming" introduced in section 4.2 could be a big step towards reaching that goal.